大模型强化学习新发现:删减84%数据反提升效果

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
在人工智能领域,"更大即更强" 的理念一直主导着大模型强化学习的发展方向。特别是在提升大语言模型的推理能力方面,业界普遍认为需要海量的强化学习训练数据才能获得突破。然而,最新研究却给出了一个令人惊喜的发现:在强化学习训练中,数据的学习影响力远比数量重要。通过分析模型的学习轨迹,研究发现精心选择的 1,389 个高影响力样本,就能超越完整的 8,523 个样本数据集的效果。这一发现不仅挑战了传统认知,更揭示了一个关键事实:提升强化学习效果的关键,在于找到与模型学习历程高度匹配的训练数据。

论文标题:LIMR: Less is More for RL Scaling
论文地址:https://arxiv.org/pdf/2502.11886
代码地址:https://github.com/GAIR-NLP/LIMR
数据集地址:https://huggingface.co/datasets/GAIR/LIMR
模型地址:https://huggingface.co/GAIR/LIMR
一、挑战传统:重新思考强化学习的数据策略
近期,强化学习在提升大语言模型的推理能力方面取得了显著成效。从 OpenAI 的 o1 到 Deepseek R1,再到 Kimi1.5,这些模型都展示了强化学习在培养模型的自我验证、反思和扩展思维链等复杂推理行为方面的巨大潜力。这些成功案例似乎在暗示:要获得更强的推理能力,就需要更多的强化学习训练数据。
然而,这些开创性工作留下了一个关键问题:到底需要多少训练数据才能有效提升模型的推理能力?目前的研究从 8000 到 150000 数据量不等,却没有一个明确的答案。更重要的是,这种数据规模的不透明性带来了两个根本性挑战:
研究团队只能依靠反复试错来确定数据量,这导致了大量计算资源的浪费
领域内缺乏对样本数量如何影响模型性能的系统性分析,使得难以做出合理的资源分配决策
这种情况促使研究团队提出一个更本质的问题:是否存在一种方法,能够识别出真正对模型学习有帮助的训练数据?研究从一个基础场景开始探索:直接从基座模型出发,不借助任何数据蒸馏(类似 Deepseek R1-zero 的设置)。通过深入研究模型在强化学习过程中的学习轨迹,研究发现:并非所有训练数据都对模型的进步贡献相同。有些数据能够显著推动模型的学习,而有些则几乎没有影响。
这一发现促使研究团队开发了学习影响力度量(Learning Impact Measurement, LIM)方法。通过分析模型的学习曲线,LIM 可以自动识别那些与模型学习进程高度匹配的 "黄金样本"。实验结果证明了这一方法的有效性:
精选的 1,389 个样本就能达到甚至超越使用 8,523 个样本的效果。
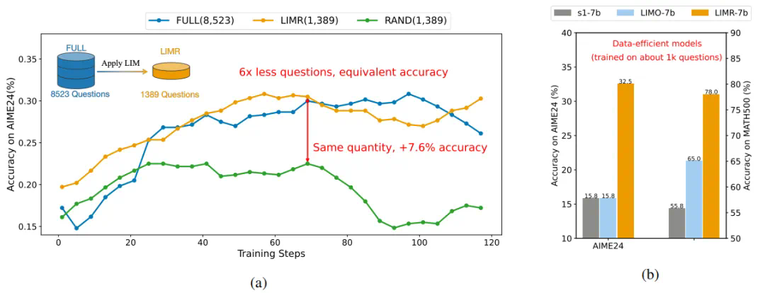
精选 1,389 个样本就能达到全量数据的效果,在小模型上强化学习优于监督微调
这些发现更新了学术界对强化学习扩展的认知:提升模型性能的关键不在于简单地增加数据量,而在于如何找到那些真正能促进模型学习的高质量样本。更重要的是,这项研究提供了一种自动化的方法来识别这些样本,使得高效的强化学习训练成为可能。
二、寻找 "黄金" 样本:数据的学习影响力测量(LIM)
要找到真正有价值的训练样本,研究团队深入分析了模型在强化学习过程中的学习动态。通过对 MATH-FULL 数据集(包含 8,523 个不同难度级别的数学问题)的分析,研究者发现了一个有趣的现象:不同的训练样本对模型学习的贡献存在显著差异。
学习轨迹的差异性
在仔细观察模型训练过程中的表现时,研究者发现了三种典型的学习模式:
部分样本的奖励值始终接近零,表明模型对这些问题始终难以掌握
某些样本能迅速达到高奖励值,显示模型很快就掌握了解决方法
最有趣的是那些展现出动态学习进展的样本,它们的奖励值呈现不同的提升速率
这一发现引发了一个关键思考:如果能够找到那些最匹配模型整体学习轨迹的样本,是否就能实现更高效的训练?
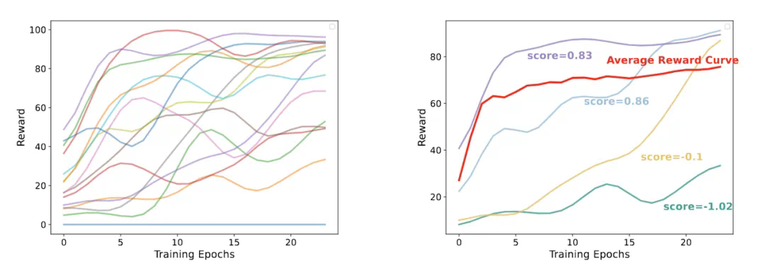
(a) 不同训练样本在训练过程中展现出的多样化学习模式。(b) 样本学习轨迹与平均奖励曲线(红色)的比较。
LIM:一种自动化的样本评估方法
基于上述观察,研究团队开发了学习影响力测量(Learning Impact Measurement, LIM)方法。LIM 的核心思想是:好的训练样本应该与模型的整体学习进程保持同步。具体来说:
1. 计算参考曲线
首先,计算模型在所有样本上的平均奖励曲线作为参考:
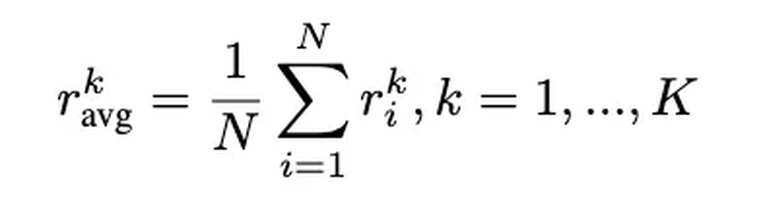
这条曲线反映了模型的整体学习轨迹。
2. 评估样本对齐度
接着,为每个样本计算一个归一化的对齐分数:
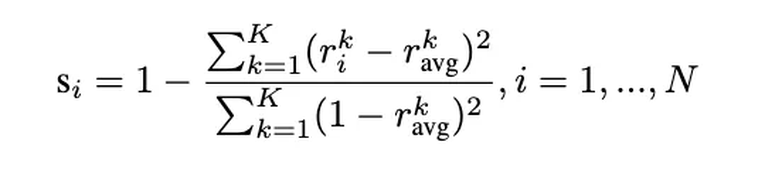
这个分数衡量了样本的学习模式与整体学习轨迹的匹配程度。分数越高,表示该样本越 "有价值"。
3. 筛选高价值样本
最后,设定一个质量阈值 θ,选取那些对齐分数超过阈值的样本。在实验中,设置 θ = 0.6 筛选出了 1,389 个高价值样本,构成了优化后的 LIMR 数据集。
对比与验证
为了验证 LIM 方法的有效性,研究团队设计了两个基线方法:
1. 随机采样(RAND):从原始数据集中随机选择 1,389 个样本
2. 线性进度分析(LINEAR):专注于那些显示稳定改进的样本
这些对照实验帮助我们理解了 LIM 的优势:它不仅能捕获稳定进步的样本,还能识别那些在早期快速提升后趋于稳定的有价值样本。
奖励设计
对于奖励机制的设计,研究团队借鉴了 Deepseek R1 的经验,采用了简单而有效的规则型奖励函数:
当答案完全正确时,给予 + 1 的正向奖励
当答案错误但格式正确时,给予 - 0.5 的负向奖励
当答案存在格式错误时,给予 - 1 的负向奖励
这种三级分明的奖励机制不仅能准确反映模型的解题能力,还能引导模型注意答案的规范性。
三、实验验证:少即是多的力量
实验设置与基准
研究团队采用 PPO 算法在 Qwen2.5-Math-7B 基座模型上进行了强化学习训练,并在多个具有挑战性的数学基准上进行了评估,包括 MATH500、AIME2024 和 AMC2023 等竞赛级数据集。
主要发现
实验结果令人振奋。使用 LIMR 精选的 1,389 个样本,模型不仅达到了使用全量 8,523 个样本训练的性能,在某些指标上甚至取得了更好的表现:
在 AIME2024 上达到了 32.5% 的准确率
在 MATH500 上达到了 78.0% 的准确率
在 AMC2023 上达到了 63.8% 的准确率
相比之下,随机选择相同数量样本的基线模型(RAND)表现显著较差,这证实了 LIM 选择策略的有效性。
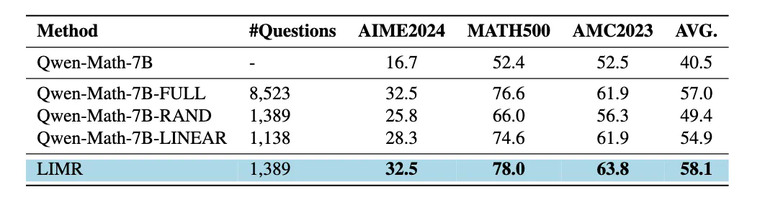
三种数据选择策略的性能对比:LIMR 以更少的数据达到更好的效果
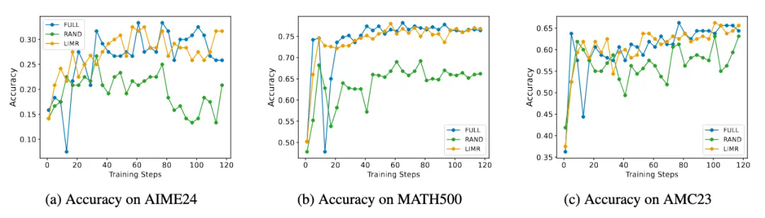
LIMR 在三个数学基准测试上的训练动态表现与全量数据相当,显著优于随机采样
训练动态分析
更有趣的是模型在训练过程中表现出的动态特征。LIMR 不仅在准确率上表现出色,其训练过程也展现出了更稳定的特征:
准确率曲线与使用全量数据训练的模型几乎重合
模型生成的序列长度变化更加合理,展现出了更好的学习模式
训练奖励增长更快,最终也达到了更高的水平
这些结果不仅验证了 LIM 方法的有效性,也表明通过精心选择的训练样本,确实可以实现 "少即是多" 的效果。
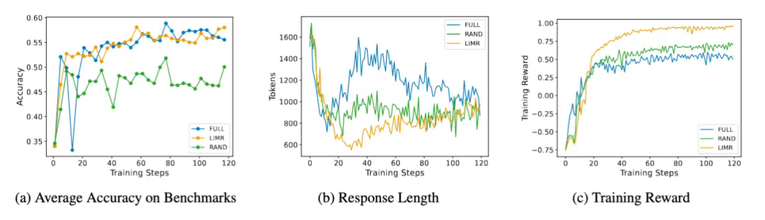
LIMR 的训练动态分析:从精选样本中获得更稳定的学习效果
四、数据稀缺场景下的新发现:RL 优于 SFT
在探索高效训练策略的过程中,研究者们发现了一个令人深思的现象:在数据稀缺且模型规模较小的场景下,强化学习的效果显著优于监督微调。
为了验证这一发现,研究者们设计了一个精心的对比实验:使用相同规模的数据(来自 s1 的 1000 条数据和来自 LIMO 的 817 条数据),分别通过监督微调和强化学习来训练 Qwen-2.5-Math-7B 模型。结果令人印象深刻:
在 AIME 测试中,LIMR 的表现较传统监督微调提升超过 100%
在 AMC23 和 MATH500 上,准确率提升均超过 10%
这些提升是在使用相近数量训练样本的情况下实现的
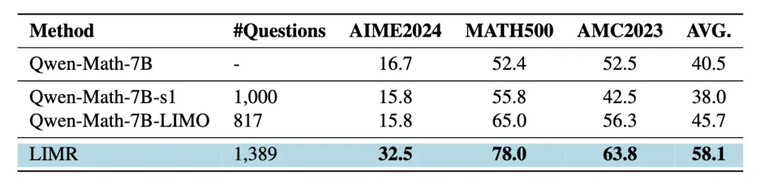
小模型上的策略对比:强化学习的 LIMR 优于监督微调方法
这一发现具有重要意义。虽然 LIMO 和 s1 等方法已经证明了在 32B 规模模型上通过监督微调可以实现高效的推理能力,但研究表明,对于 7B 这样的小型模型,强化学习可能是更优的选择。
这个结果揭示了一个关键洞见:在资源受限的场景下,选择合适的训练策略比盲目追求更具挑战性的数据更为重要。通过将强化学习与智能的数据选择策略相结合,研究者们找到了一条提升小型模型性能的有效途径。
参考资料:https://github.com/GAIR-NLP/LIMR
声明:本文转载自机器之心,转载目的在于传递更多信息,并不代表本社区赞同其观点和对其真实性负责,本文只提供参考并不构成任何建议,若有版权等问题,点击这里查看更多信息!