OpenAI:强化学习确实可显著提高LLM性能,DeepSeek R1、Kimi k1.5发现o1的秘密
最近,OpenAI 发了一篇论文,宣称 o3 模型在 2024 IOI 上达到了金牌水平,并且在 CodeForces 上获得了与精英级人类相当的得分。
他们是怎么做到的呢?OpenAI 在论文开篇就用一句话进行了总结:「将强化学习应用于大型语言模型(LLM)可显著提高在复杂编程和推理任务上的性能。」

论文标题:Competitive Programming with Large Reasoning Models 论文地址:https://arxiv.org/pdf/2502.06807
这两天,这篇论文又引起了广泛热议,尤其是其中被博主 Matthew Berman 指出的关键:这种策略不仅适用于编程,它还是通往 AGI 及更远未来的最清晰路径。

也就是说,这篇论文不仅仅是展示了 AI 编程的新成绩,更是给出了一份创造世界最佳 AI 程序员乃至 AGI 的蓝图。正如 OpenAI 在论文中写到的那样:「这些结果表明,扩展通用强化学习,而不是依赖特定领域的技术,能为在推理领域(例如竞技编程)实现 SOTA AI 提供一条稳健的路径。」
此外,这篇论文还特别提到,中国的 DeepSeek-R1 和 Kimi k1.5 通过独立研究显示,利用思维链(CoT)学习方法可显著提升模型在数学解题与编程挑战中的综合表现,这也是 o1 此前没有公开过的「配方」—— 直到前些天才半遮半掩地揭示一些,参阅机器之心报道《感谢 DeepSeek,ChatGPT 开始公开 o3 思维链,但不完整》。(1 月 20 日,DeepSeek 和 Kimi 在同一天发布推理模型 R1 和 k1.5,两个模型均有超越 OpenAI o1 的表现。)

下面,我们先看看这篇论文的核心内容,然后再看看 Matthew Berman 为什么说扩展通用强化学习是「通往 AGI 及更远未来的最清晰路径」。
OpenAI 从自家的三个模型入手,这三个模型分别是 o1 、 o1-ioi 以及 o3。
OpenAI o1 :
在竞争性编程任务上的性能大幅提升
o1 是一个通过强化学习训练的大型语言模型,旨在解决复杂的推理任务。
在回答问题之前,o1 会先生成一个内部思维链,并且用强化学习完善这种思维链过程,帮助模型识别和纠正错误,将复杂任务分解为可管理的部分,并在一种方法失败时探索替代的解决方案路径。这些上下文推理能力显著提升了 o1 在广泛任务上的整体表现。
Kimi 研究员 Flood Sung 也谈到了推理模型 Kimi k1.5 的研发过程也有类似的发现,他指出:「长思维链的有效性曾在 Kimi 内部得到验证,使用很小的模型,训练模型做几十位的加减乘除运算,将细粒度的运算过程合成出来变成很长的 CoT 数据做 SFT,就可以获得非常好的效果。」他说,「依然记得当时看到那个效果的震撼。」
除此之外,o1 还可调用外部工具验证代码。
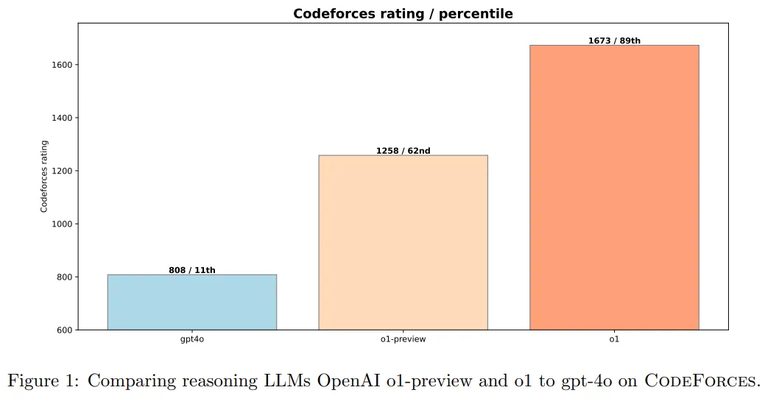
不同模型在 CodeForces 基准上的表现。
OpenAI 将 o1 与非推理型大语言模型(gpt-4o)以及早期的推理模型(o1-preview)进行了对比。
图 1 展示了 o1-preview 和 o1 都显著优于 gpt-4o,这凸显了强化学习在复杂推理任务中的有效性。
o1-preview 模型在 CodeForces 上的评分达到了 1258 分,相比 gpt-4o 的 808 分有了显著提升。进一步的训练将 o1 的评分提升至 1673,为 AI 在竞争性编程中的表现树立了新的里程碑。
OpenAI o1-ioi:
增加强化学习和测试时推理就能带来大幅提升
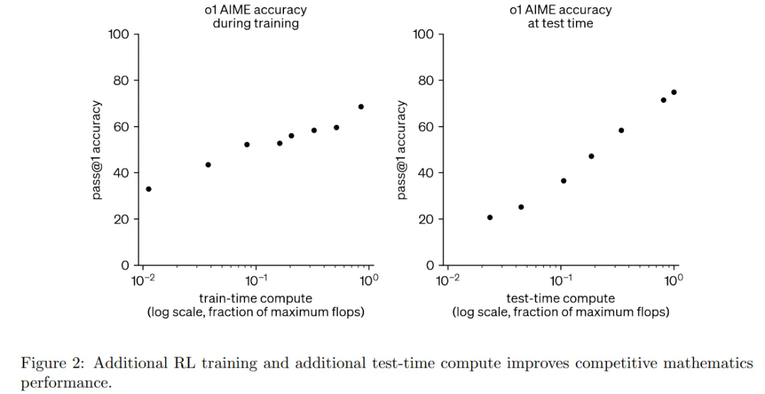
OpenAI 在开发和评估 OpenAI o1 的过程中,他们发现增加 RL 计算量和测试时推理计算量都能持续提升模型性能。
如图 2 所示,扩展 RL 训练和延长测试时推理可以显著提升模型性能。基于这些洞见,OpenAI 创建了 o1-ioi 系统。
他们从以下方面来实现。
第一步是扩展 OpenAI o1 的强化学习阶段,重点关注编码任务。具体如下:
从 OpenAI o1 检查点开始继续强化学习训练; 特别强调了具有挑战性的编程问题,帮助模型改进 C++ 生成和运行时检查。 指导模型以 IOI 提交格式生成输出。
在高层次上,OpenAI 将每个 IOI 问题分解为子任务,并为每个子任务从 o1-ioi 中采样了 10,000 个解决方案,然后采用基于聚类和重新排名的方法来决定从这些解决方案中提交哪些。
图 3 显示,o1-ioi 的 CodeForces 评分达到 1807,超过 93% 的竞争对手 —— 这证明了在编码任务上进行额外的 RL 训练可以带来明显的改进。
这些结果证实,特定领域的 RL 微调与高级选择启发式相结合可以显著提高编程结果。
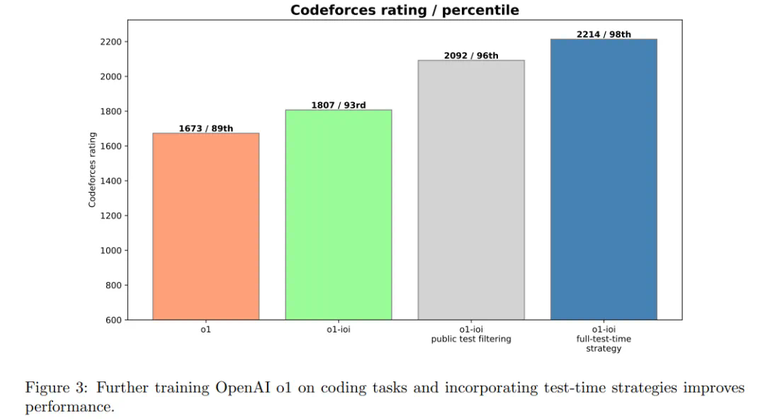
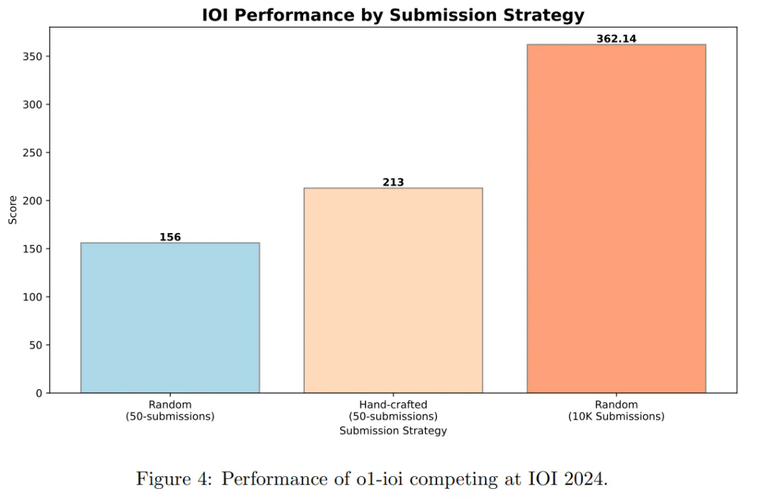
图 4 为 IOI 比赛结果。在比赛期间,系统为每道问题生成了 10,000 个候选解决方案,并使用测试时选择策略从中筛选出 50 次提交。最终,模型获得了 213 分,排名位于前 49 % 。
OpenAI o3:
无需人类的强化学习效果卓越
基于从 o1 和 o1-ioi 获得的洞见,OpenAI 又探索了仅依赖强化学习(RL)结果如何,而不依赖于人为设计的测试时策略。
甚至 OpenAI 试图探索进一步的 RL 训练,模型是否能够自主开发和执行自己的测试时推理策略。
为此,OpenAI 使用了 o3 的早期检查点,以评估其在竞技编程任务上的表现。
如图 5 所示,进一步的强化学习(RL)训练显著提升了 o1 和完整 o1-ioi 系统的表现。o3 能够以更高的可靠性解决更广泛的复杂算法问题,使其能力更接近 CodeForces 上的顶级人类程序员。
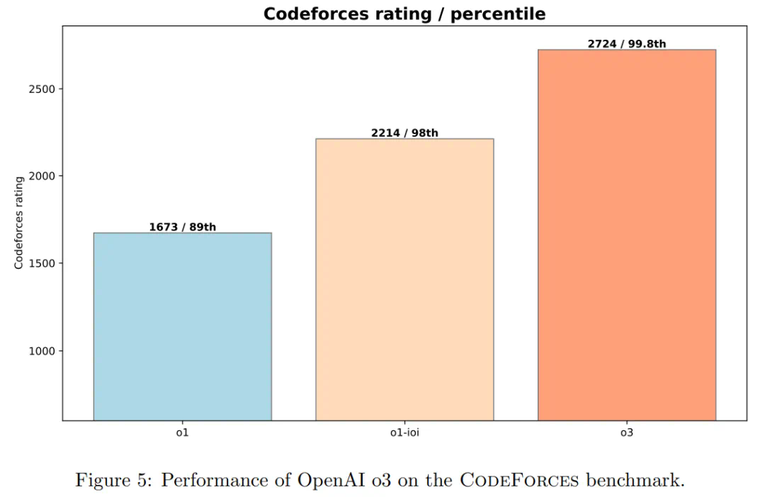
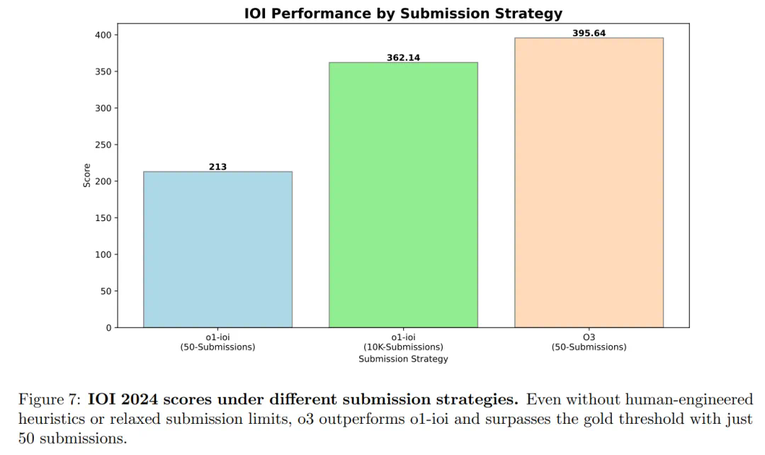
图 7 为模型在 IOI 2024 上的最终得分。2024 年比赛的总分上限为 600 分,金牌的分数线约为 360 分。
以下是关键结果:
o1-ioi 在 50 次提交的限制下获得了 213 分,而在 10,000 次提交的限制下提升至 362.14 分,略高于金牌分数线。
o3 在 50 次提交的限制下获得了 395.64 分,超过了金牌分数线。
这些结果表明,o3 在不依赖针对 IOI 手工设计的测试时策略的情况下,表现优于 o1-ioi。相反,o3 在训练过程中自然涌现的复杂测试时技术(例如生成暴力解法以验证输出)足以替代 o1-ioi 所需的手工设计的聚类和选择流程。
总体而言,在 IOI 2024 上的结果证实,仅通过大规模强化学习训练即可实现最先进的编程和推理性能。通过独立学习生成、评估和优化解决方案,o3 超越了 o1-ioi,而无需依赖领域特定的启发式方法或基于聚类的方法。
另外,在 CodeForces 上,如前图 5 所示,o3 的成绩达到了 2724 分,已经进入了全球前 200 名。
该论文的作者之一 Ahmed El-Kishky 在 𝕏 上分享了一个有趣的发现。他表示,他们在检查思维链时发现该模型独立发展出了自己的测试时策略:该模型首先会编写一个简单的暴力解决方案,然后再使用它来验证一种更加复杂优化版方法。

软件工程评估
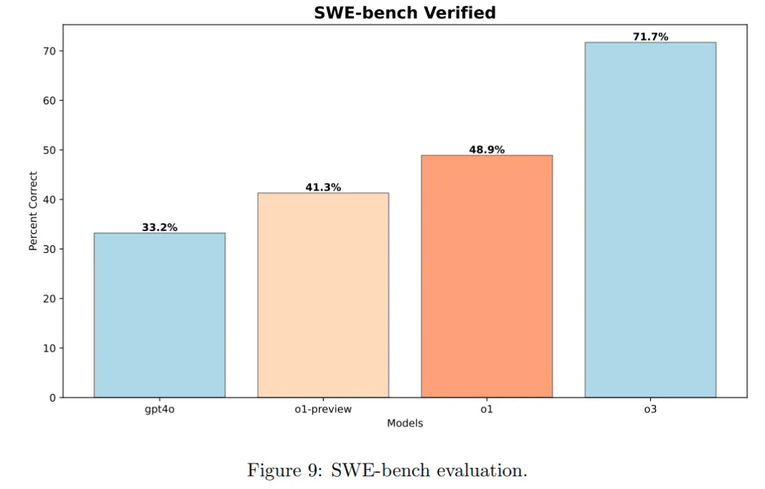
OpenAI 还对模型进行了软件工程评估。他们在两个数据集上测试了模型:HackerRank Astra 数据集和 SWE-bench verified。
图 8 表明了模型进行思维链推理的影响:与 GPT-4o 相比,o1-preview 模型在 pass@1 上提升了 9.98%,在平均得分上提高了 6.03 分。
通过强化学习进一步微调后,o1 的表现得到了提升,其 pass@1 达到了 63.92%,平均得分为 75.80%—— 相比 o1-preview,pass@1 提高了 3.03%。
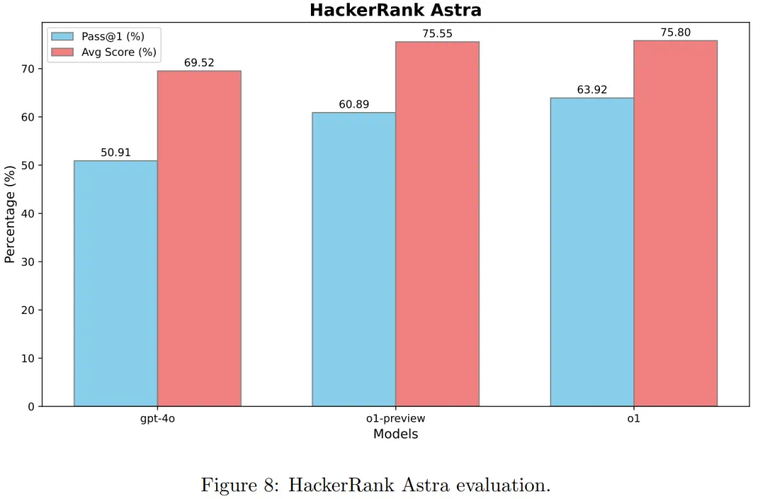
图 9 所示,o1 预览版在 SWE-bench 上相比 gpt-4o 提升了 8.1%,突显了模型推理能力的显著进步。
在训练过程中应用额外的强化学习计算,o1 进一步实现了 8.6% 的性能提升。
值得注意的是,o3 使用了比 o1 显著更多的计算资源进行训练,比 o1 实现了 22.8% 的显著改进。
通用强化学习是实现 AGI 的最清晰路径?
基于此论文,Matthew Berman 通过一系列推文佐证了一个论点:通用强化学习是实现 AGI 的最清晰路径。下面我们来看看他的论据。
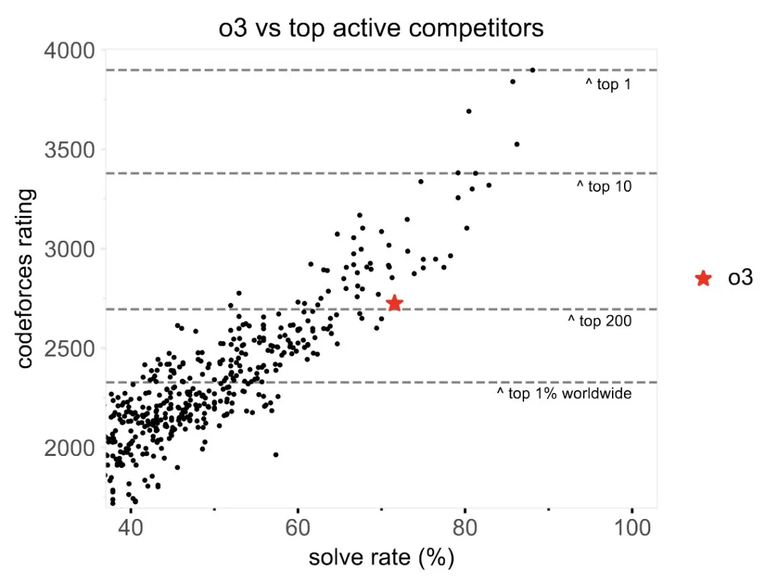
首先,在这篇论文中,OpenAI 的研究表明「强化学习 + 测试时计算」是构建超智能 AI 的关键。OpenAI CEO Sam Altman 也说 OpenAI 的模型已经在竞争性编程任务上从 175 名上升到了 50 名,并有望在今年底达到第 1 名。
视频来自 𝕏 @tsarnick
同时,上述论文中也指出,一开始模型依赖于人类设计的推理策略,但进步最大时候并不是在这个阶段出现的,而是在将人类完全移出流程之后。
Berman 也引出了 DeepSeek-R1 的巨大成就。

他指出,DeepSeek-R1 的突破来自于「可验证奖励的强化学习」,而这其实也是 AlphaGo 使用的方法 —— 让模型在试错中学习,然后无限地扩展智能。
AlphaGo 在没有人类引导的情况下成为了世界最强围棋棋手。它的方法就是不断与自己博弈,直到其掌握这个游戏。

Kimi 研究员 Flood Sung 也谈到了这一点,他指出:「不管模型中间做错了什么,只要不是重复的,最后模型做对了就认为这是一个好的探索,值得鼓励。反之,要惩罚。随后在实际训练中,发现模型会随着训练提升表现并不断增加 token 数,证明强化训练过程中模型可以自己涌现,这与 DeepSeek 的发现非常相似,也为 k1.5 视觉思考模型的上线奠定了基础。」
而现在,类似的策略也被 OpenAI 用在了编程领域,并且未来也可能被用在更多领域。
这意味着什么呢?Berman 认为,这意味着每个具有可验证奖励的领域(包括数学、编程、科学)都可被 AI 通过自我博弈方法掌握。
Flood Sung 也表达了类似的期待:「o3 在前面,还有很多路要走。给 AI 一个可衡量的目标,然后让其自己去探索。比如让 AI 写出 10 万 + 的公众号文章,比如让 AI 发布一个复制 tiktok 的 app,让我们一起期待一下接下来的进展!」
届时,AI 将不再受到人类水平的限制。这或许也就是 AGI 诞生之时。
实际上,特斯拉已经在全自动驾驶任务上验证这一点了。过去,他们的方法是依靠一个「人类规则 + AI」的混合模型;但他们换成端到端的 AI 方法之后,性能实现了大幅提升。Berman 表示:「AI 只需要更多计算 —— 而不是更多人类干预。」
正如 Sam Altman 之前说过的那样,AGI 就是个规模扩展问题。
实际上,已经有不少研究者将强化学习用在编程和数学等领域之外了。

当然,并不是所有人都认可 Berman 与 Altman 的看法,比如有人指出了竞争性编程与实际编程的区别 —— 实际编程往往涉及到更多问题,包括可扩展性、安全性、弹性和投资回报等。

也有人直言反驳:

你已经看过这篇论文了吗?对于「可验证奖励的强化学习」的未来潜力,你有什么看法?你认为这能否实现 AGI?
声明:本文转载自机器之心,转载目的在于传递更多信息,并不代表本社区赞同其观点和对其真实性负责,本文只提供参考并不构成任何建议,若有版权等问题,点击这里查看更多信息!