AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
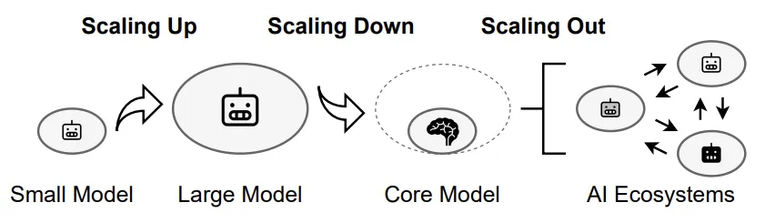
本文由悉尼大学计算机学院王云柯,李言蹊和徐畅副教授完成。王云柯是悉尼大学博士后,李言蹊是悉尼大学三年级博士生,徐畅副教授是澳洲ARC Future Fellow,其团队长期从事机器学习算法、生成模型等方向的研究。近年来, Scaling Up 指导下的 AI 基础模型取得了多项突破。从早期的 AlexNet、BERT 到如今的 GPT-4,模型规模从数百万参数扩展到数千亿参数,显著提升了 AI 的语言理解和生成等能力。然而,随着模型规模的不断扩大,AI 基础模型的发展也面临瓶颈:高质量数据的获取和处理成本越来越高,单纯依靠 Scaling Up 已难以持续推动 AI 基础模型的进步。为了应对这些挑战,来自悉尼大学的研究团队提出了一种新的 AI Scaling 思路,不仅包括 Scaling Up(模型扩容),还引入了 Scaling Down(模型精简)和 Scaling Out(模型外扩)。Scaling Down 通过优化模型结构,使其更轻量、高效,适用于资源有限的环境,而 Scaling Out 则致力于构建去中心化的 AI 生态系统,让 AI 能力更广泛地应用于实际场景。- 论文标题:AI Scaling: From Up to Down and Out
- 论文链接:https://www.arxiv.org/abs/2502.01677
该框架为未来 AI 技术的普及和应用提供了新的方向。接下来,本文将详细探讨这一框架如何推动 AI Scaling 从集中化走向分布式,从高资源消耗走向高效普及,以及从单一模型衍生 AI 生态系统。Scaling Up: 模型扩容,持续扩展基础模型Scaling Up 通过增加数据规模、模型参数和计算资源,使 AI 系统的能力得到了显著提升。然而,随着规模的不断扩大,Scaling Up 也面临多重瓶颈。数据方面,高质量公开数据已被大量消耗,剩余数据多为低质量或 AI 生成内容,可能导致模型性能下降。模型方面,参数增加带来的性能提升逐渐减弱,大规模模型存在冗余、过拟合等问题,且难以解释和控制。计算资源方面,训练和推理所需的硬件、能源和成本呈指数级增长,环境和经济压力使得进一步扩展变得不可持续。尽管面临挑战,规模化扩展仍是推动 AI 性能边界的关键。未来的趋势将聚焦于高效、适应性和可持续性的平衡:数据优化:通过课程学习、主动学习等技术,利用更小规模的高质量数据集实现高效训练。同时,处理噪声数据和利用领域专有数据将成为突破点。高效训练:采用渐进式训练、分布式优化和混合精度训练等方法,减少资源消耗,提升训练效率,推动 AI 开发的可持续性。Test-Time Scaling:通过在推理阶段动态分配计算资源,提升模型性能。例如,自适应输出分布和验证器搜索机制使小型模型在某些任务上超越大型模型,为高效 AI 提供了新方向。AI Scaling Up 的未来不仅在于「更大」,更在于「更智能」和「更可持续」。通过优化数据、训练和推理流程,AI 有望在突破性能边界的同时,实现更广泛的应用和更低的环境成本。Scaling Down: 模型精简,聚焦核心模块随着 Scaling Up 所需的训练、部署和维护计算资源、内存和能源成本急剧增加,一个关键问题浮出水面:如何在缩小模型规模的同时,保持甚至提升其性能?Scaling Down 旨在减少模型规模、优化计算效率,同时保持核心能力,使 AI 适用于更广泛的资源受限场景,如边缘设备和移动端应用。1. 减少模型规模:剪枝,通过移除神经网络中不重要的部分来简化模型;量化,将浮点参数替换为整数,减少权重和激活的比特宽度;知识蒸馏,将大型复杂模型的知识迁移到小型高效模型中。2. 优化计算效率:投机采样,通过近似模型生成候选词,再由目标模型并行验证,加速推理过程;KV Caching,存储注意力机制的中间状态,避免重复计算;混合专家模型,通过任务特定的子模型和门控机制实现高效扩展。例如,DeepSeek-V3 通过专家模型的选择性激活,显著降低推理过程中的计算成本。未来这一领域的研究可能聚焦以下方向。首先,核心功能模块的提炼将成为重点。未来的研究将致力于识别大型模型中的关键功能模块,力求在保留核心功能的前提下,最大限度地减少冗余结构。通过系统化的剪枝和知识蒸馏技术,开发出更精细的模型架构优化方法,从而在缩小规模的同时不损失性能。其次,外部辅助增强将为小模型提供新的能力扩展途径。例如,检索增强生成(RAG)技术通过结合预训练的参数化记忆和非参数化记忆,使模型能够动态获取上下文相关信息;而工具调用技术则让小模型学会自主调用外部 API,甚至生成自己的工具以应对复杂任务。Scaling Out: 模型外扩,构建 AI 生态系统在 Scaling Up 和 Scaling Down 之后,文章提出 Scaling Out 作为 AI Scaling 的最后一步,其通过将孤立的基础模型扩展为具备结构化接口的专业化变体,将其转化为多样化、互联的 AI 生态系统。在该生态系统中,接口负责连接专业化模型与用户、应用程序和其他 AI 系统。这些接口可以是简单的 API,也可以是能够进行多轮推理和决策的 Agent。通过结合基础模型、专用变体和接口,Scaling Out 构建了一个动态的 AI 生态系统,包含多个 AI 实体在其中交互、专业化并共同提升智能。这一生态促进了协作,能够实现大规模部署,并不断拓展 AI 的能力,标志着 AI 向开放、可扩展、去中心化的智能基础架构转变。1. 参数高效微调:传统的微调需要大量计算资源,但参数高效微调技术如 LoRA 允许在不修改整个模型的情况下添加任务特定知识。2. 条件控制:使基础模型能够动态适应多种任务,而无需为每个任务重新训练。例如,ControlNet 通过结构引导生成上下文感知图像。3. 联邦学习:支持在分布式设备上协作训练 AI 模型,确保数据隐私和安全。联邦学习允许在多样化、领域特定的数据集上训练专业化子模型,增强其适应能力。未来这一领域的研究可能聚焦于以下方向。首先,去中心化 AI 和区块链 。AI 模型商店将像应用商店一样提供多样化模型,区块链则作为信任层,确保安全性、透明性和知识产权保护。每一次微调、API 调用或衍生模型创建都将被记录在不可篡改的账本上,确保信用归属和防止未经授权的修改。其次,边缘计算与分布式智能。边缘计算在本地设备上处理数据,减少对集中式数据中心的依赖。结合联邦学习,边缘计算能够在保护隐私的同时,实现实时决策和分布式智能。人机共创社区如 TikTok 等,将迎来智能内容创作的新纪元。内容创作者不再仅限于人类,AI 驱动的 Bots 将成为重要组成部分。这些 Bots 能够自主生成高质量短视频,与其他用户互动,甚至彼此协作,推动内容创作的多样性与复杂性。Scaling Up 是整个体系的基石,通过整合 TikTok 全球用户的多模态数据,开发出强大的多模态基础模型,为 Bots 提供内容生成、互动和创意的核心能力。然而,仅靠一个巨型模型难以满足多样化需求,Scaling Down 将基础模型的核心能力提炼为轻量化模块,使 AI Bots 能够高效、灵活地执行任务,降低计算成本并适应多样化场景部署。最终,Scaling Out 将 TikTok 推向智能生态的全新高度。通过任务驱动的生成机制,平台能够快速扩展出数以万计的专用 Bots,每个 Bot 都针对特定领域(如教育、娱乐、公益)进行了深度优化。这些 Bots 不仅可以单独运行,还能通过协作网络共享知识,构建实时进化的内容网络,为用户提供无穷无尽的创意和互动体验。此外,文中探讨了 AI Scaling 在跨学科合作、量化标准、开放生态、可持续性和公平性方面的机遇与难点。AI Scaling 需要跨学科合作,结合认知科学、神经科学、硬件工程和数据科学,提升计算效率和适应性。同时,需要建立量化标准,例如评估模型大小、计算成本与性能的关系,为 AI 发展提供清晰的参考。开放生态是 AI Scaling 发展的关键,轻量级核心模型和开放 API 可以促进 AI 在医疗、农业、工业等行业的落地应用。为了实现可持续发展,Scaling Down 通过轻量化 AI 减少能耗,Scaling Out 则通过分布式和多接口扩展,降低对数据中心的依赖,从而提升全球可及性。最终,AI Scaling 将为通用人工智能(AGI)奠定基础。Scaling Up 提供基础知识,Scaling Down 提高适应性,Scaling Out 构建开放、去中心化的 AI 生态系统,该系统中的不同接口相互协同,共同应对复杂挑战。
大模型扩展新维度:Scaling Down、Scaling Out -
行业动态 - 资讯 -
AI 中文社区
声明:本文转载自机器之心,转载目的在于传递更多信息,并不代表本社区赞同其观点和对其真实性负责,本文只提供参考并不构成任何建议,若有版权等问题,点击这里查看更多信息!本站拥有对此声明的最终解释权。如涉及作品内容、版权和其它问题,请联系我们删除,我方收到通知后第一时间删除内容。