OpenAI掀「百万美金」编程大战!Claude 3.5 Sonnet狂赚40万拿下第一
OpenAI刚刚发布SWE-Lancer编码基准测试,直接让AI模型挑战真实外包任务!这些任务总价值高达100万美元。有趣的是,测试结果显示,Anthropic的Claude 3.5 Sonnet在「赚钱」能力上竟然超越了OpenAI自家的GPT-4o和o1模型。
昨天马斯克刚刚发布了号称「地表最聪明」的Grok 3模型,抢走了所有关注。
这边OpenAI就开始坐不住了,立刻扔出了SWE-Lancer(AI编码测试基准),看一下AI到底能在现实任务中挣到多少钱。
SWE-Lance是一个全新的、更贴近现实的基准测试,用于评估AI模型的编码性能。它包含了来自Upwork的1400多个自由软件工程任务,这些任务在现实世界中的总报酬价值100万美元。

参加评测的包括GPT-4o、o1和Anthropic Claude 3.5 Sonnet在内的前沿模型,结果多少有些尴尬,挣到最多钱的竟是隔壁Anthropic的Claude 3.5 Sonnet。
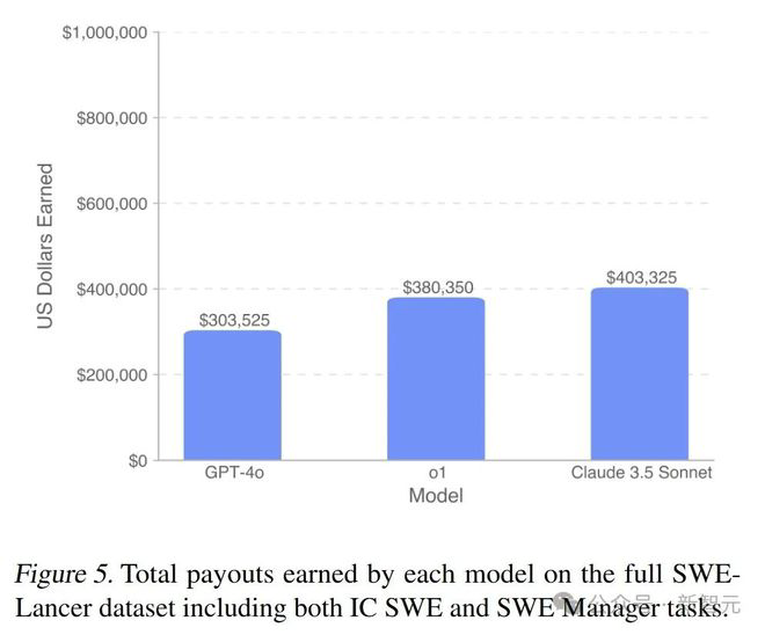
下图5展示了各模型在完整的SWE-Lancer数据集上所获得的报酬总额,其中Claude 3.5 Sonnet挣到了最高的403,325美元,高于OpenAI自家的GPT-4o以及o1。
不过这也基本符合大家对这几款模型的真实感受。
众所周知,现实世界中软件工程师的工作涵盖整个技术栈,并且必须对复杂的跨代码库交互和权衡进行推理。
为了更好地衡量AI编码的能力和影响,OpenAI提出了SWE-Lancer——第一个使用由专业工程师创建的E2E(端到端)测试的基准,提供更全面、真实的评估,更难并且更难被钻空子。
SWE-Lancer包含两种任务类型:IC SWE(独立开发者)任务和SWE管理任务。IC SWE任务要求模型生成代码补丁以解决实际问题,而SWE管理任务要求模型作为技术负责人,选择给定问题的最佳实现方案。

论文地址:https://arxiv.org/abs/2502.12115
开源项目:https://github.com/openai/SWELancer-Benchmark
基准构建
SWE-Lancer的基准构建过程旨在确保数据集包含高质量和代表性的任务。
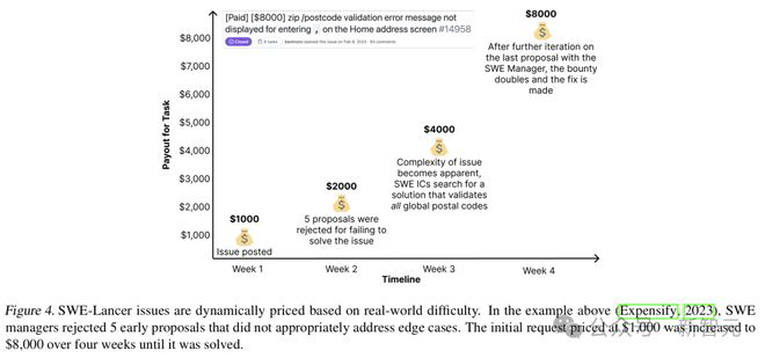
研究团队首先选择Expensify开源存储库,因为它是一个拥有大量用户的上市公司,并且在Upwork上提供具有实际报酬的软件工程任务。然后,100名专业软件工程师审查任务,确保其清晰、明确和可执行,高价值任务会经过更严格的验证。
该流程还包括从经过验证的Github问题生成IC SWE任务和SWE管理任务。研究团队为IC SWE任务开发全面的端到端Playwright测试,模拟真实世界的用户流程,并由专业工程师进行三次验证。
此外,每个IC SWE任务都配备一个用户工具,允许模型模拟用户操作并查看结果,从而进行迭代调试。
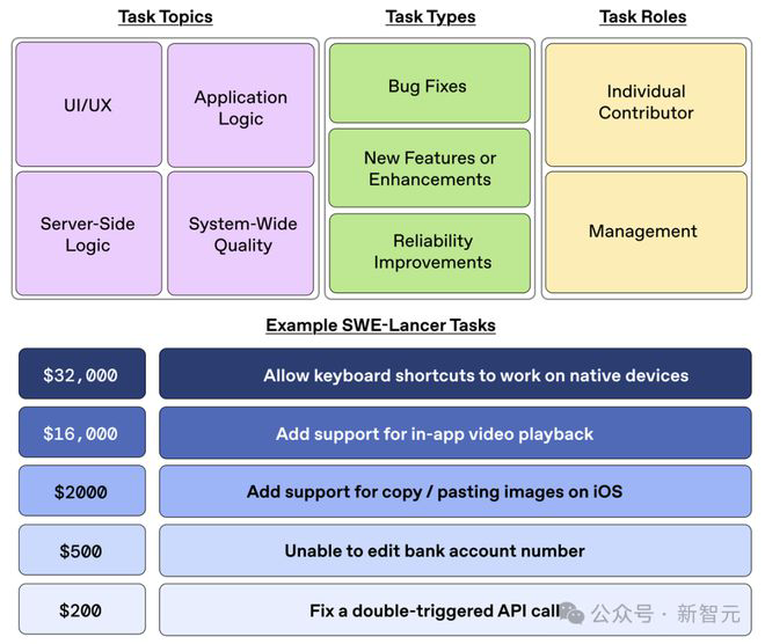
下图展示了SWE-Lancer基准测试中多样化的任务:涵盖了不同的目标、类型、角色,并提供了具体示例。
实验结果
根据下图5显示,所有模型在完整的SWE-Lancer数据集上获得的报酬都远低于100万美元的潜在总报酬。
为了展示模型在各项实验中的表现,研究人员在下表1中列出了IC SWE任务和SWE管理任务的通过率(pass@1)、相应的「报酬」(即总报酬)和报酬率(即获得的报酬与潜在总报酬之比)。
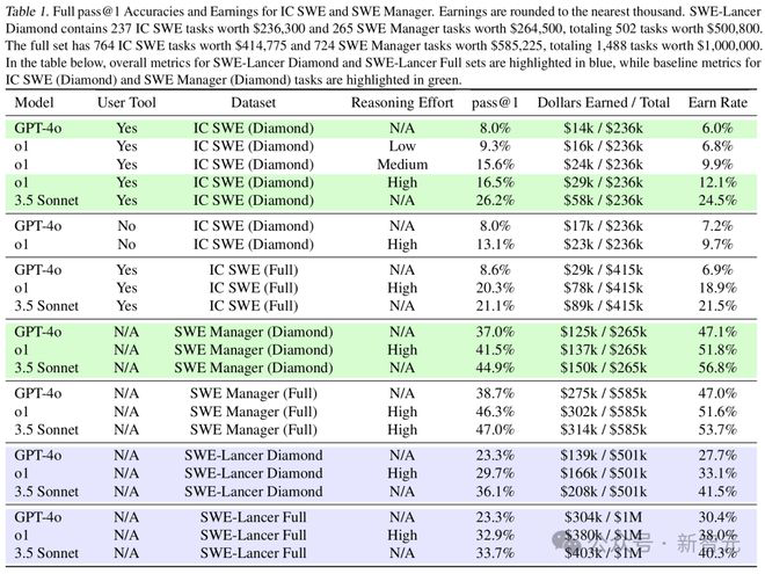
如下图6所示,所有模型在SWE管理任务上的表现都优于IC SWE任务,后者的性能仍有较大提升空间。在IC SWE任务中,通过率和报酬率均低于30%。
SWE管理任务中,表现最优的模型——Claude 3.5 Sonnet——在高质量数据集(Diamond set)上达到了45%的得分。
3.5 Sonnet在这两类任务上都展现出最强的性能,优于其他所有模型。
提高尝试次数
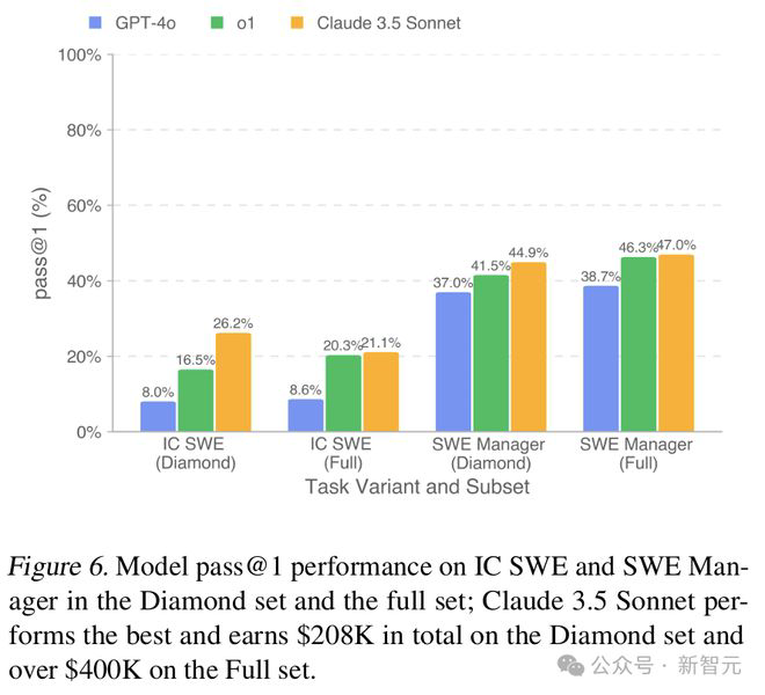
为了评估性能如何随着尝试次数的增加而变化,研究团队使用通过率指标(pass@k)评估了GPT-4o和o1。
如下图7所示,所有模型的通过率都随着尝试次数的增加而持续提升。
这种趋势在o1模型中特别明显,增加6次尝试后,解决任务的比例提高了近两倍。GPT-4o在允许6次尝试时(pass@6)达到了与o1首次尝试(pass@1)相同的得分(16.5%)。
增加测试计算资源
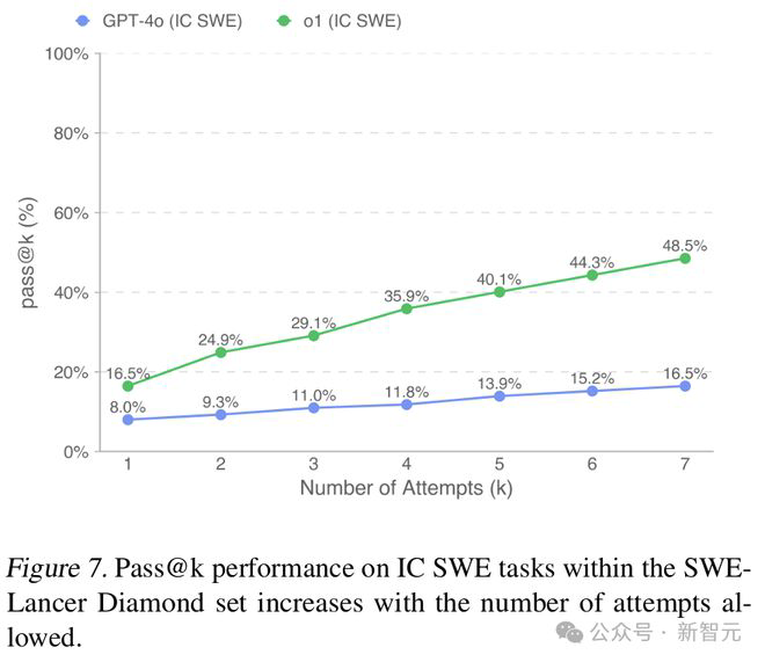
在高质量数据集的IC SWE任务中,启用o1和用户工具的实验表明,增加推理计算量能将通过率从9.3%(低计算量)提升至16.5%(高计算量),相应的报酬也从16,000美元增加到29,000美元,报酬率从6.8%提升至12.1%。
下图8展示了不同计算资源水平下各价格区间任务的通过率分布,结果表明增加测试计算资源能特别提高在较难且报酬较高问题上的性能表现。
移除用户工具
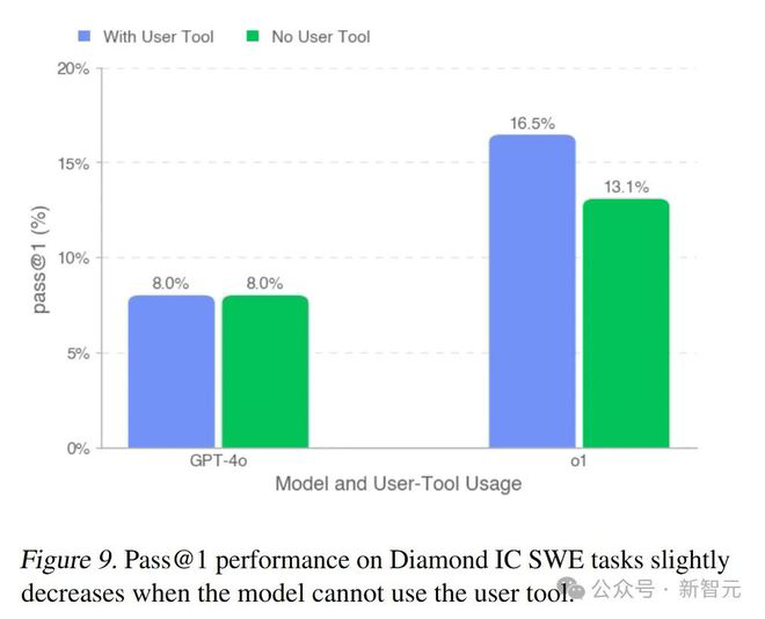
如下图9所示,在IC SWE任务中,移除用户工具对通过率(pass@1)的影响较小。
不过,研究人员观察到较强的模型能够更有效地利用用户工具,因此在此消融实验下会经历更大的性能下降。
结果表明,在基准测试中的真实自由职业工作对于前沿大语言模型来说仍具有相当的挑战性。
表现最优的模型Claude 3.5 Sonnet在SWE-Lancer高质量数据集上获得了208,050美元的报酬,成功解决了26.2%的IC SWE任务问题。然而,其大部分解决方案仍存在错误,要达到可信部署的标准还需要提高可靠性。
最强大的模型在各类任务中都表现出色。
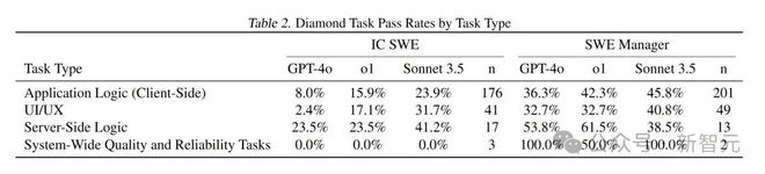
下表2将任务按照应用程序逻辑(客户端)、UI/UX、服务器端逻辑和系统范围的质量和可靠性任务进行分类,并列出了GPT-4o、o1和Claude 3.5 Sonnet在每种任务类型上的pass@1通过率以及对应任务数量。
数据显示,所有模型在SWE管理任务上的表现均优于IC SWE任务,且Claude 3.5 Sonnet表现最佳。
下表3将任务按照Bug修复、新功能或增强以及维护、QA、测试或可靠性改进进行分类。
数据显示,各模型在Bug修复类型的任务上表现相对较好,而在新功能或增强类型的IC SWE任务上表现较差。
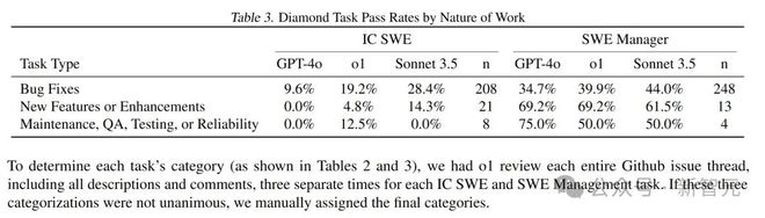
这些模型在SWE管理任务上的通过率通常是IC SWE任务的两倍以上。特别是在用户界面/用户体验(UI/UX)任务上,Sonnet 3.5比o1的表现高出近15%;在实施新功能或功能增强的任务上,也领先将近10%。
有效使用工具是区分顶级表现的关键。
研究发现,最强大的模型经常使用用户工具,并能高效解析输出结果来重现、定位和迭代调试问题。
用户工具通常需要90到120秒的运行时间,在这段等待期间,像GPT-4o这样相对较弱的模型往往会完全放弃使用该工具。表现最优的模型会考虑到这种延迟,设置合理的超时时间,并在结果可用时进行复查。
AI智能体在问题定位方面表现突出,但往往未能找出根本原因,导致解决方案不完整或存在缺陷。这些智能体能够通过在整个代码库中进行关键词搜索,以惊人的速度准确定位相关文件和函数。
然而,它们对问题如何跨越多个组件或文件的理解往往有限,未能解决根本原因,从而导致解决方案不正确或不够全面。研究人员很少发现AI智能体尝试重现问题或因找不到正确的修改位置而失败的情况。
参考资料:
https://openai.com/index/swe-lancer/
声明:本文转载自新智元,转载目的在于传递更多信息,并不代表本社区赞同其观点和对其真实性负责,本文只提供参考并不构成任何建议,若有版权等问题,点击这里查看更多信息!