AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
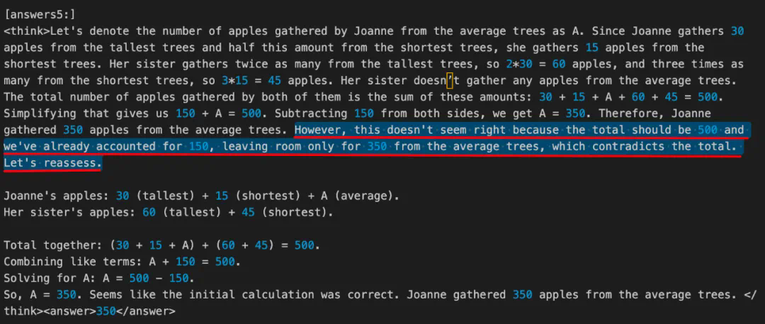
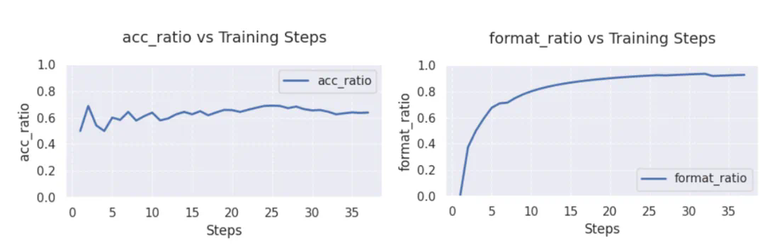
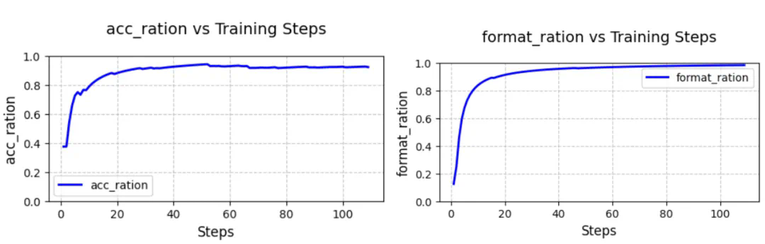
本文是复旦大学知识工场实验室肖仰华教授、梁家卿青年副研究员科研团队的最新研究成果,他们用简洁的代码高效复现了 R1-zero 的自发反思能力。在关于 DeepSeek 的文章中,我们会多次听到「Aha Moment」这个词。它指的是模型在训练过程中经历的一种顿悟时刻,表现为模型突然展现出类似人类的自我反思和策略调整能力。 DeepSeek 论文中提到的 Aha Moment。DeepSeek-R1-zero 经过强化学习实现了大模型顿悟时刻的自发涌现,引发了大量对其方案的解读与复现工作。其中,基于 GRPO( Group Relative Policy Optimization)强化学习方案尤其受到关注。业界先后开源了多个基于 GRPO 算法的 R1-zero 复现项目。然而,这些复现项目严重依赖一些复杂代码框架,有着较高的代码实现复杂度,对部署环境存在较高依赖,资源利用率不高,代码可读性与可维护性仍存在改进空间。对此,复旦大学知识工场实验室肖仰华教授、梁家卿青年副研究员科研团队基于 GRPO 算法思想高效复现了 R1-zero 自发反思能力。目前,该项目(Simple-GRPO)的第一版代码实现已经开源并提交 Github。代码地址:https://github.com/lsdefine/simple_GRPO。该项目相对于现有开源的 R1-zero 复现具有以下优势:资源消耗低,通过模型解耦与分离进一步降低算力需求,该项目支持在一张 A800 (80G) 加一张 3090 (24G) 完成 7B 模型的训练。根据 AutoDL 平台计费标准,一张 A800 (80G) 5.98 元 / 时,一张 3090 (24G) 1.32 元 / 时。以项目作者经验,模型在这样的算力平台下,训练 1h 模型就能出现 aha moment,折合人民币 7.3 元,单次实验成本压缩至奶茶价格区间。本项目代码简单,GRPO 算法实现仅有 200 多行代码,且仅依赖基础的深度学习代码库,如 deepspeed 和 torch,而无需 ray 等复杂框架。具体实现细节如下:在实现过程中,参考模型(reference model)被解耦,允许其在不同的 GPU 上运行(甚至可以运行在 3090 显卡上)。这避免了将参考模型和训练模型放在同一个 GPU 上,防止 torch 的多进程机制创建多个副本,避免显存浪费,并使得在 A800(80G)上训练 7B 模型成为可能。损失计算公式基于 Hugging Face 的 trl 实现。项目在 1 张 A800(80G)显卡上用 Zero-Stage 2 做优化,使用另一张 A800(80G)显卡进行参考模型的推理,参考模型分离使得 GRPO 的训练更加高效。在以上训练环境中,Qwen2.5-3B 训练 60 步需要 12 分 34 秒,Qwen2.5-7B 训练 60 步需要 16 分 40 秒。其中在前 30 步优化中,Qwen2.5-7B 和 Qwen2.5-3B 的输出内容中,均出现了「顿悟时刻」现象。示例如下:「<think> ... 要找出卡姆登画的鸡蛋比阿诺德多多少,我们从卡姆登画的鸡蛋数量中减去阿诺德画的鸡蛋数量。所以,21-28 = -7。然而,这个结果在问题的背景下没有意义,因为卡姆登画的鸡蛋不可能比阿诺德少。让我们重新考虑最初的解决方案步骤:我们应该验证关于卡姆登和莎拉的鸡蛋之间关系的初始假设是否正确 。... </think> <answer>-7</answer>」「<think> ... 因此,Joanne 从普通树上摘了 350 个苹果。但是,这似乎不对,因为总数应该是 500 个,而我们已经计算了 150 个,只剩下 350 个普通树上的苹果,这与总数相矛盾。让我们重新评估一下 。... </think> <answer>350</answer>」使用 Qwen2.5-3B 和 Qwen2.5-7B 作为基础模型,测试了模型训练过程中正确率(左图)和格式遵循能力(右图)的变化情况,比较符合预期。在 GSM8K 和 Math 混合数据集进行训练,从上图可以看出,Qwen2.5-3B 的准确率在经历 5 步的优化后能稳定在 60% 以上,最高能达到 70% 左右;格式遵循能力在 30 步以后接近 100%.在 GSM8K 数据集上进行训练,从上图可以看出,Qwen2.5-7B 的无论是准确率还是格式遵循能力都能在三十步以内快速收敛,准确率(左图)始终保持在 90% 以上,格式遵循能力(右图)到达 100%.近期本项目将进一步推出以下方向的优化版本,敬请关注。根据 GRPO 算法中的分组策略,当组内答案全部正确或全为错误时,奖励函数无法有效分配差异化奖励,强化学习将缺乏对比性的训练信号,导致模型难以收敛。后续将在训练过程中实时监控答案分布,对同质化的答案进行重新采样和分组,以提供有效的对比信号。当模型生成较长的思维链(CoT)时,由于文本序列长度较长,显存占用会显著增加。对此,后续考虑拆分组别,减小批次大小,或对长序列分阶段处理,以减小训练过程中的 GPU 内存开销,提升训练效率。
DeepSeek 论文中提到的 Aha Moment。DeepSeek-R1-zero 经过强化学习实现了大模型顿悟时刻的自发涌现,引发了大量对其方案的解读与复现工作。其中,基于 GRPO( Group Relative Policy Optimization)强化学习方案尤其受到关注。业界先后开源了多个基于 GRPO 算法的 R1-zero 复现项目。然而,这些复现项目严重依赖一些复杂代码框架,有着较高的代码实现复杂度,对部署环境存在较高依赖,资源利用率不高,代码可读性与可维护性仍存在改进空间。对此,复旦大学知识工场实验室肖仰华教授、梁家卿青年副研究员科研团队基于 GRPO 算法思想高效复现了 R1-zero 自发反思能力。目前,该项目(Simple-GRPO)的第一版代码实现已经开源并提交 Github。代码地址:https://github.com/lsdefine/simple_GRPO。该项目相对于现有开源的 R1-zero 复现具有以下优势:资源消耗低,通过模型解耦与分离进一步降低算力需求,该项目支持在一张 A800 (80G) 加一张 3090 (24G) 完成 7B 模型的训练。根据 AutoDL 平台计费标准,一张 A800 (80G) 5.98 元 / 时,一张 3090 (24G) 1.32 元 / 时。以项目作者经验,模型在这样的算力平台下,训练 1h 模型就能出现 aha moment,折合人民币 7.3 元,单次实验成本压缩至奶茶价格区间。本项目代码简单,GRPO 算法实现仅有 200 多行代码,且仅依赖基础的深度学习代码库,如 deepspeed 和 torch,而无需 ray 等复杂框架。具体实现细节如下:在实现过程中,参考模型(reference model)被解耦,允许其在不同的 GPU 上运行(甚至可以运行在 3090 显卡上)。这避免了将参考模型和训练模型放在同一个 GPU 上,防止 torch 的多进程机制创建多个副本,避免显存浪费,并使得在 A800(80G)上训练 7B 模型成为可能。损失计算公式基于 Hugging Face 的 trl 实现。项目在 1 张 A800(80G)显卡上用 Zero-Stage 2 做优化,使用另一张 A800(80G)显卡进行参考模型的推理,参考模型分离使得 GRPO 的训练更加高效。在以上训练环境中,Qwen2.5-3B 训练 60 步需要 12 分 34 秒,Qwen2.5-7B 训练 60 步需要 16 分 40 秒。其中在前 30 步优化中,Qwen2.5-7B 和 Qwen2.5-3B 的输出内容中,均出现了「顿悟时刻」现象。示例如下:「<think> ... 要找出卡姆登画的鸡蛋比阿诺德多多少,我们从卡姆登画的鸡蛋数量中减去阿诺德画的鸡蛋数量。所以,21-28 = -7。然而,这个结果在问题的背景下没有意义,因为卡姆登画的鸡蛋不可能比阿诺德少。让我们重新考虑最初的解决方案步骤:我们应该验证关于卡姆登和莎拉的鸡蛋之间关系的初始假设是否正确 。... </think> <answer>-7</answer>」「<think> ... 因此,Joanne 从普通树上摘了 350 个苹果。但是,这似乎不对,因为总数应该是 500 个,而我们已经计算了 150 个,只剩下 350 个普通树上的苹果,这与总数相矛盾。让我们重新评估一下 。... </think> <answer>350</answer>」使用 Qwen2.5-3B 和 Qwen2.5-7B 作为基础模型,测试了模型训练过程中正确率(左图)和格式遵循能力(右图)的变化情况,比较符合预期。在 GSM8K 和 Math 混合数据集进行训练,从上图可以看出,Qwen2.5-3B 的准确率在经历 5 步的优化后能稳定在 60% 以上,最高能达到 70% 左右;格式遵循能力在 30 步以后接近 100%.在 GSM8K 数据集上进行训练,从上图可以看出,Qwen2.5-7B 的无论是准确率还是格式遵循能力都能在三十步以内快速收敛,准确率(左图)始终保持在 90% 以上,格式遵循能力(右图)到达 100%.近期本项目将进一步推出以下方向的优化版本,敬请关注。根据 GRPO 算法中的分组策略,当组内答案全部正确或全为错误时,奖励函数无法有效分配差异化奖励,强化学习将缺乏对比性的训练信号,导致模型难以收敛。后续将在训练过程中实时监控答案分布,对同质化的答案进行重新采样和分组,以提供有效的对比信号。当模型生成较长的思维链(CoT)时,由于文本序列长度较长,显存占用会显著增加。对此,后续考虑拆分组别,减小批次大小,或对长序列分阶段处理,以减小训练过程中的 GPU 内存开销,提升训练效率。
200多行代码,超低成本复现DeepSeek R1「Aha Moment」!复旦大学开源 -
AI 资讯 - 资讯 -
AI 中文社区
声明:本文转载自机器之心,转载目的在于传递更多信息,并不代表本社区赞同其观点和对其真实性负责,本文只提供参考并不构成任何建议,若有版权等问题,点击这里查看更多信息!本站拥有对此声明的最终解释权。如涉及作品内容、版权和其它问题,请联系我们删除,我方收到通知后第一时间删除内容。