打破AI遗忘诅咒的学习算法,慕尼黑-南大团队打造会自主积累知识的学习框架

编辑丨&
人类可以在一生中不断积累知识并发展越来越复杂的行为和技能,这种能力被称为「终身学习」。
这种终身学习能力被认为是构成一般智能的基本机制,但人工智能的最新进展主要在狭窄的专业领域表现出色,对于这种终身学习能力显得有些缺乏。
慕尼黑大学与南京大学的研究团队联手打造了一款机器人终身强化学习框架,它通过开发一个受贝叶斯非参数域启发的知识空间来解决这一差距。
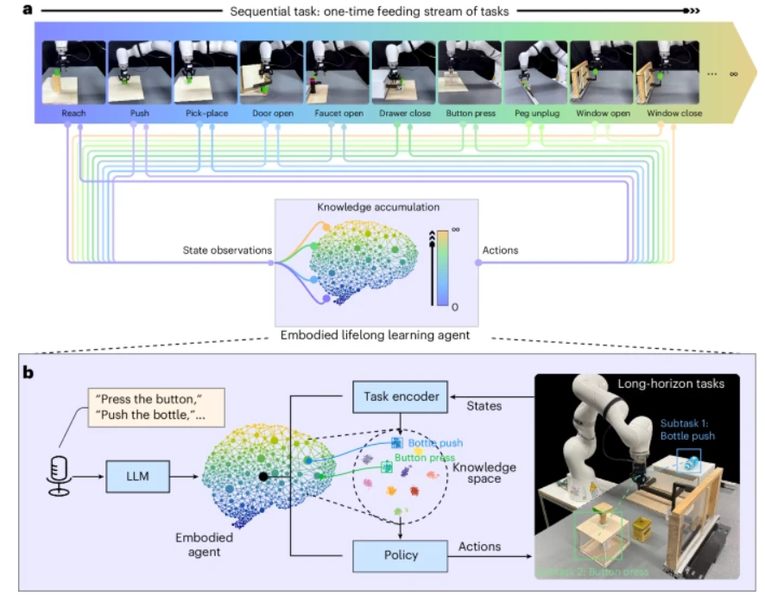
语言集成被嵌入到该框架中以增强代理对任务的语义理解,团队所提出的具身代理可以从连续的一次性喂养任务流中持续积累知识。
该成果以「Preserving and combining knowledge in robotic lifelong reinforcement learning」为题,于 2025 年 2 月 5 日发布于《Nature Machine Intelligence》。

代理可以通过组合和重新应用其从原始任务流中获得的知识来处理具有挑战性的现实世界长期任务。拟议的框架有助于促进对机器人终身学习过程的理解,激发更广泛适用的智能的发展。
机器人终身强化学习
人类通过不断获取知识和适应不同的环境来获得非凡的学习能力,这种学习行为涉及到益不断的复杂行为和渐进发展,被认为是实现一般智能的关键机制。
尽管当今人工智能代理在各种任务中取得了卓越的表现,但实际上它们主要关注专门从事狭义分布式任务的代理。未经训练的代理在其整个生命周期中通常比人类需要更多的训练时长,而且难以有效地进行推广。
本研究侧重于机器人终身强化学习 (LRL)。在这个领域,强化学习提供了一个非常适合按顺序探索学习过程的代理-环境交互框架。
图示:机器人 LRL 过程的概念图。(图源:论文)
对于基于深度学习的算法,对一系列任务时的主要挑战是平衡稳定性和可塑性神经网络。而在这种情况下,「灾难性遗忘」导致的前学习的技能相关的神经网络参数被快速覆盖的现象成为了常见的问题。
在深度强化学习的背景下,避免「灾难性遗忘」的一个常见想法是通过多任务强化学习 (MTRL)。在 MTRL 中,代理在训练期间可以同时访问所有任务,从而避免了深度神经网络中固有的遗忘问题。
虽然 MTRL 试图通过同时提供来自各种任务的数据来避免灾难性遗忘的问题,但这个问题在顺序学习过程中仍然存在。
团队将他们的框架命名为 LEGION:一种基于语言嵌入的具有非参数贝叶斯的生成增量非策略强化学习框架。它展示了自己实现通用智能的潜力,并可能激发开发更广泛适用的智能代理。
LEGION 框架的测试
对于长距离任务,团队采用了 KUKA iiwa 机械臂作为实施例,并使用全局 RealSense 摄像头来获取视觉信息。代理通过重新组合从一次性喂养任务流中获得的底层知识来实现本次任务,展示了它在面对多样化和具有挑战性的任务分配时的有效泛化。

对于给定的一连串的一次性喂食任务,LRL 代理可以接连不断地完成任务,而不会忘记以前获得的知识。这种增量学习方法模仿了自然的人类学习过程,有可能在实际应用中取代并最终超越低效的手动服务。
对于一些难度较高的挑战任务,代理模型也可以保证较高的完成率。
知识保存
在这个框架中,任务编码器最初推断状态输入并生成潜在样本作为推理结果,随后推断的任务结果被拟合到非参数知识空间中。
在知识空间中提出的 DPMM 模块可以在切换环境时生成新组件来存储新的任务推理结果,从而促进推理和存储新知识的能力。代理执行的两次循环有助于评估此前获得的知识。
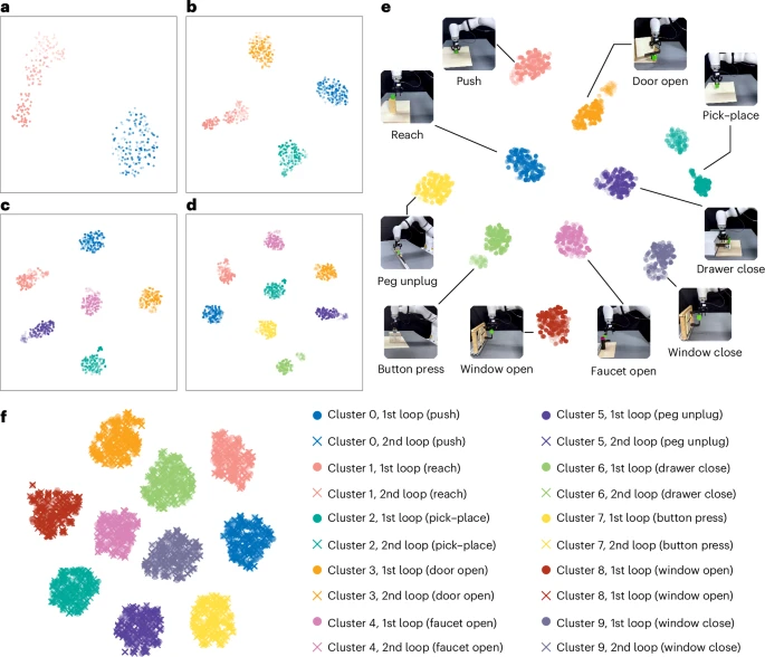
在代理的终身学习过程中,团队还观察到积极的向前转移现象。具体来说,对于「抽屉关闭」任务,早期从「推」、「拾取-放置」和「开门」等任务中获得的知识有助于「抽屉关闭」的成功。
此外,知识排练也是终身学习的重要组成部分。最近计算机视觉方面的研究已经表明,排练可以有效地减轻学习过程中的遗忘。
多个任务的持续改进强调了代理模型在重新掌握任务和保持高成功率方面的稳健性,展示了框架的潜力,尤其是 DPMM 在推进 LRL 方面的知识空间。
小结
机器人终身学习侧重于从连续的任务流中获取和保留知识,使代理能够通过知识集成和重用逐步构建更复杂的行为。而本次实验团队提出了一个深度强化学习框架,它从一系列任务中不断积累知识,展示了类似人类的终身学习能力。
在 LRL 框架中,可以通过可视化和统计的角度分析知识管理。知识空间中的非参数模型通过创建或合并组件来动态调整以适应新的任务输入,从而确保持续的知识保存,而无需先验知识量。从数量上讲,代理的成功率随着时间的推移而提高,证明了 LRL 中的有效知识积累。
框架 LEGION 在终身学习期间,擅长在贝叶斯非参数知识空间中保存知识和推断新任务。使用语言嵌入来帮助任务推理,代理可以有效地执行长期任务,展示基于积累的知识处理复杂任务的灵活性。
研发团队表示,使用非参数知识空间从一系列任务中不断学习和保留技能的能力,结合扩散模型的平滑和稳定的下游动作输出,可以为开发广泛适用的大型行为模型提供更加强大的动力。
此外,由于他们工作的假设方向,还有另一个有前途的探索方向,即使用 LLM 在终身学习过程中不断完善奖励。
论文链接:https://www.nature.com/articles/s42256-025-00983-2
声明:本文转载自机器之心,转载目的在于传递更多信息,并不代表本社区赞同其观点和对其真实性负责,本文只提供参考并不构成任何建议,若有版权等问题,点击这里查看更多信息!